WebScraper 4.15.6

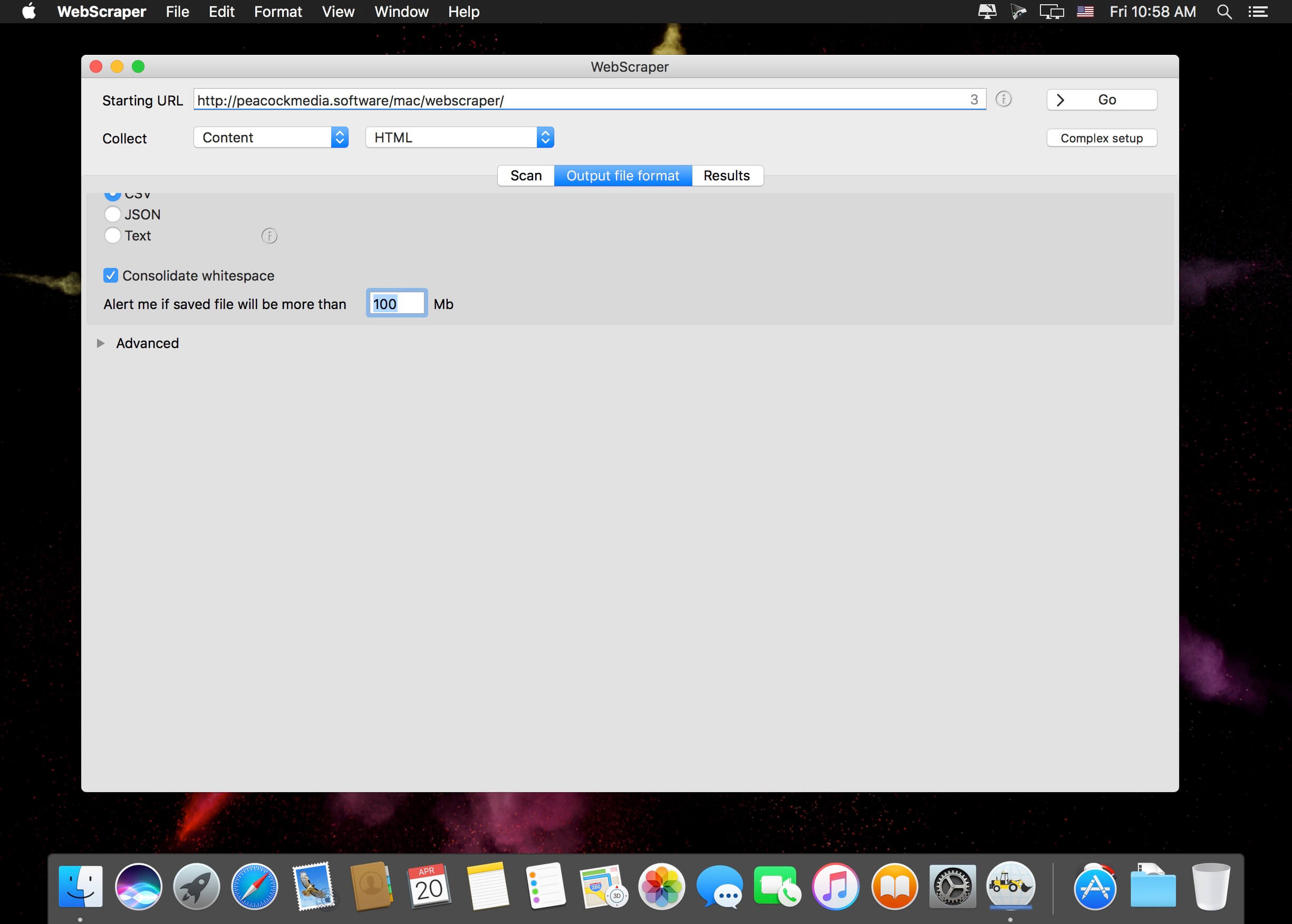
WebScraper uses the Integrity v8 engine to quickly scan a website, and can output extracted data (currently) as CSV or JSON. Plus download images to a folder.
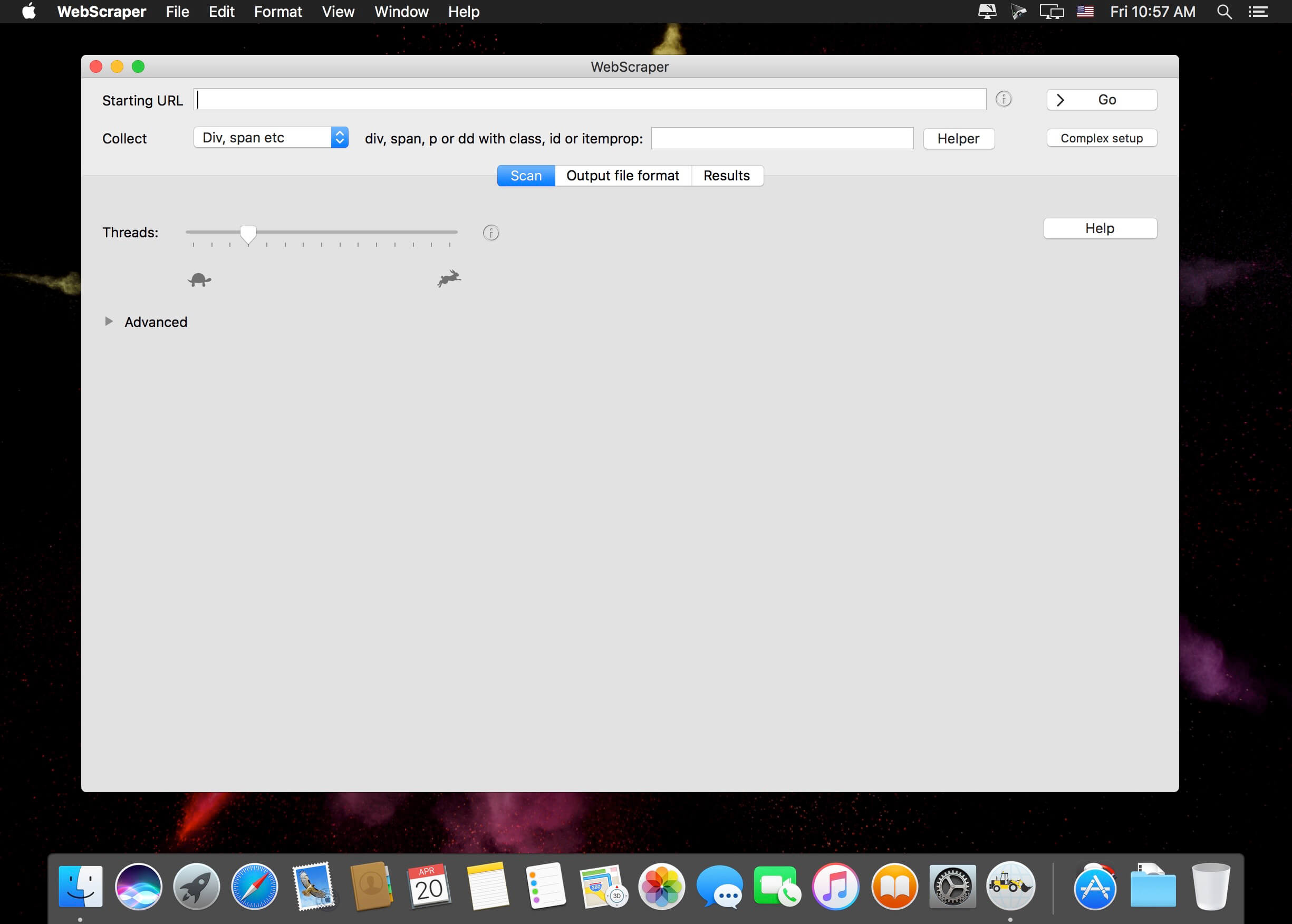
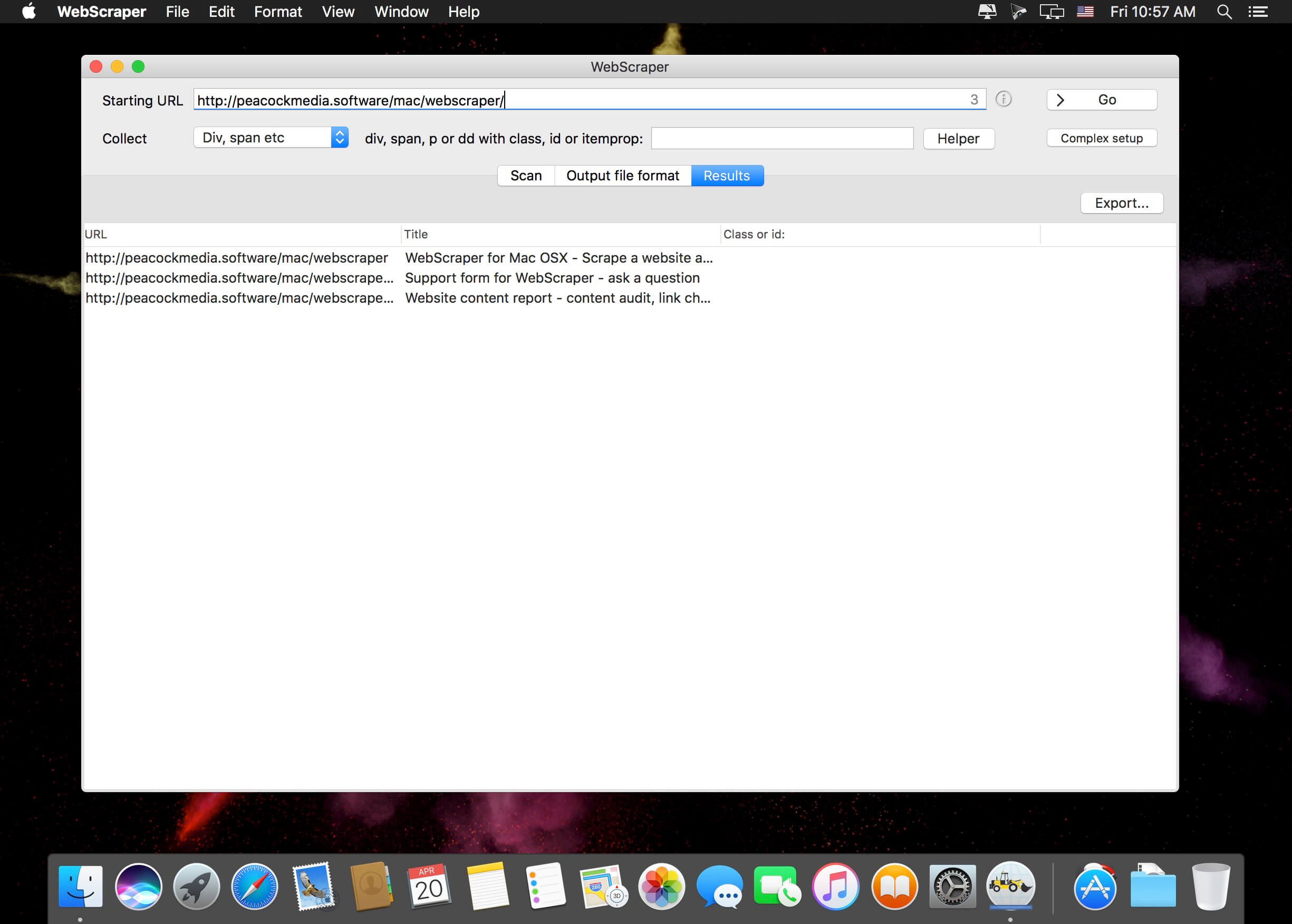
- Easy to scan a site - just enter the starting URL and press "Go"
- Easy to export - choose the columns you want
- Plenty of extraction options, including HTML elements with certain classes or IDs, regular expressions, or entire content in a number of formats (html, plain text, markdown)
- Since v4.1 can download to a folder all images discovered
- Configuration of various limits on the crawl and the output file size
- More…
What's New:
Version 4.15.5
- Fix for output filtering based on term in the content.
Screenshots:
- Title: WebScraper 4.15.6
- Developer: PeacockMedia
- Compatibility: macOS 10.10 or later
- Language: English
- Includes: K'ed by HCiSO
- Size: 4.69 MB
- visit official website

Comments 1
Users of Guests are not allowed to comment this publication.