Geekbench 4.4.1

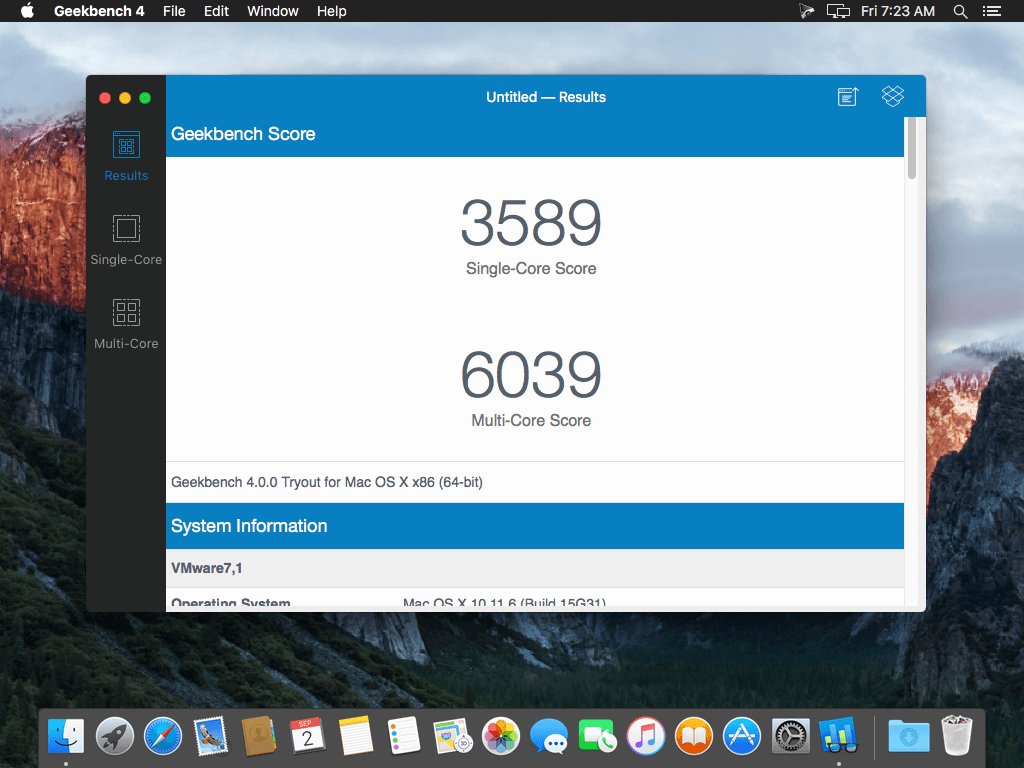
Geekbench provides a comprehensive set of benchmarks engineered to quickly and accurately measure processor and memory performance. Designed to make benchmarks easy to run and easy to understand, Geekbench takes the guesswork out of producing robust and reliable benchmark results.
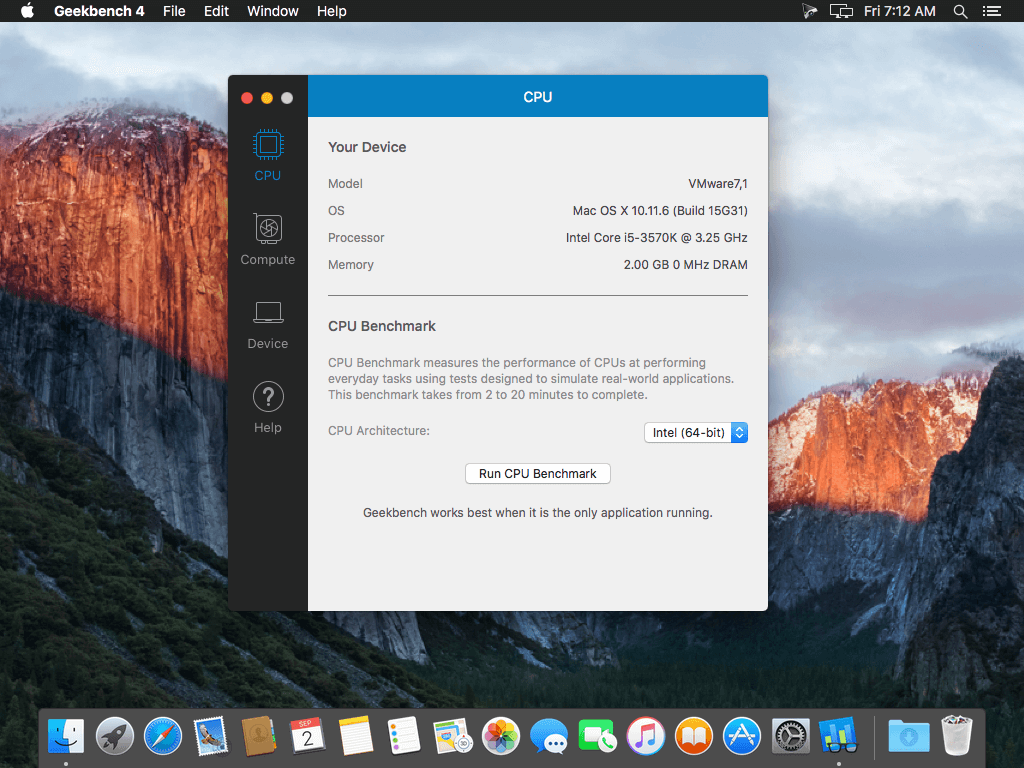
CPU Benchmark
Each CPU workload models a real-world task or application, ensuring meaningful results. These tests are complex, avoiding simple problems with straightforward memory-access patterns, and push the limits of your system.
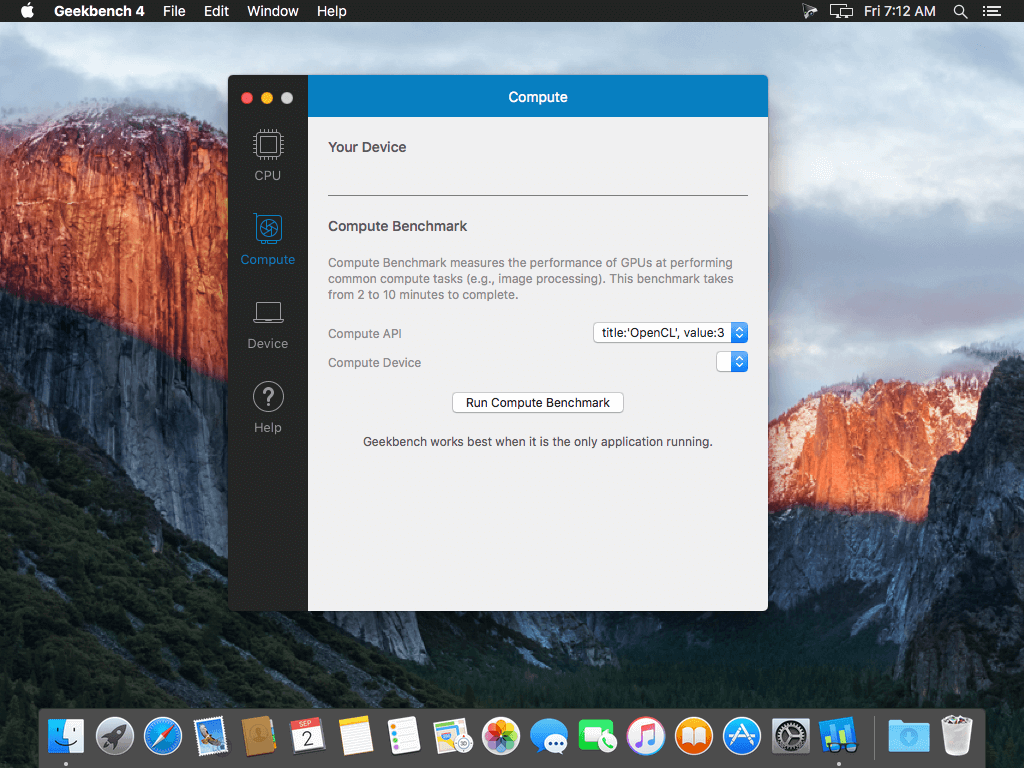
Compute Benchmark
Measure the compute performance of your GPU with the new Compute Benchmark. From image processing to computer vision to number crunching, Geekbench 4 tests your GPU using relevant and complex challenges.
Cross-Platform
Designed from the ground-up for cross-platform comparisons, Geekbench 4 allows you to compare system performance across devices, processor architectures, and operating systems. Geekbench 4 supports Android, iOS, macOS, Windows, and Linux.
What's New:
Version 4.4.1:- Update comparison results to include the latest Android, iOS devices
Screenshots:
- Title: Geekbench 4.4.1
- Developer: Primate Labs Inc.
- Compatibility: OS X 10.11.4 or later, 64-bit processor
- Language: English
- Includes: K'ed by TNT
- Size: 78.16 MB
- visit official website

Users of Guests are not allowed to comment this publication.