Warp 4.2

Warp allows you to convert and analyze (very) large databases with ease at the speed of light. In Warp, you work on a small subset of the data, after which Warp repeats your actions on the entire dataset. Unlike most data analysis apps, you do not have to type any codes in Warp.
- Read data from files (e.g. CSVs), databases (MySQL, PostgreSQL or SQLite) or even big data warehouses (RethinkDB and Facebook Presto)
- Effortlessly juggle around data between files and databases by simply dragging-and-dropping! Load CSV files into MySQL or transfer a PostgreSQL table to a RethinkDB table by just dragging one to the other.
- Efficiently analyze large datasets: Warp works closely together with databases to deliver the best performance.
- Work faster by creating your analysis on a small subset of the data, then run it on all data with only a single click
- Use the same formulas and techniques (such as pivot tables) you already know from Microsoft Excel™
- Easily re-run an analysis on different data, possibly from different sources
- Easy-to-use, drag and drop interface, but the pro features are never more than a click away
What's New:
Version 4.0:
- Work more easily with data sets in zoomed mode!
- Use SSH tunnels to connect to MySQL databases
- Warp now supports CockroachDB
Screenshots:
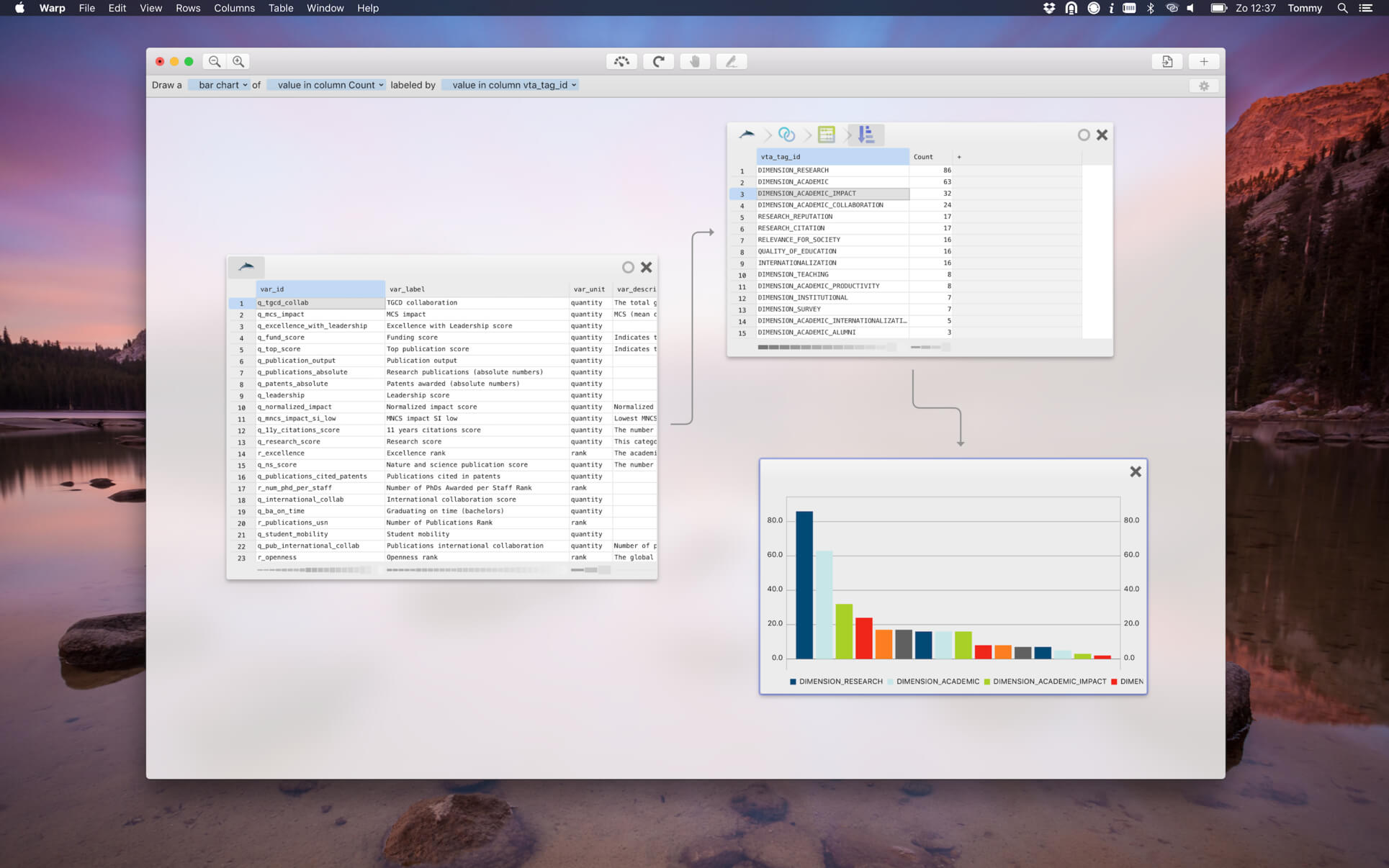
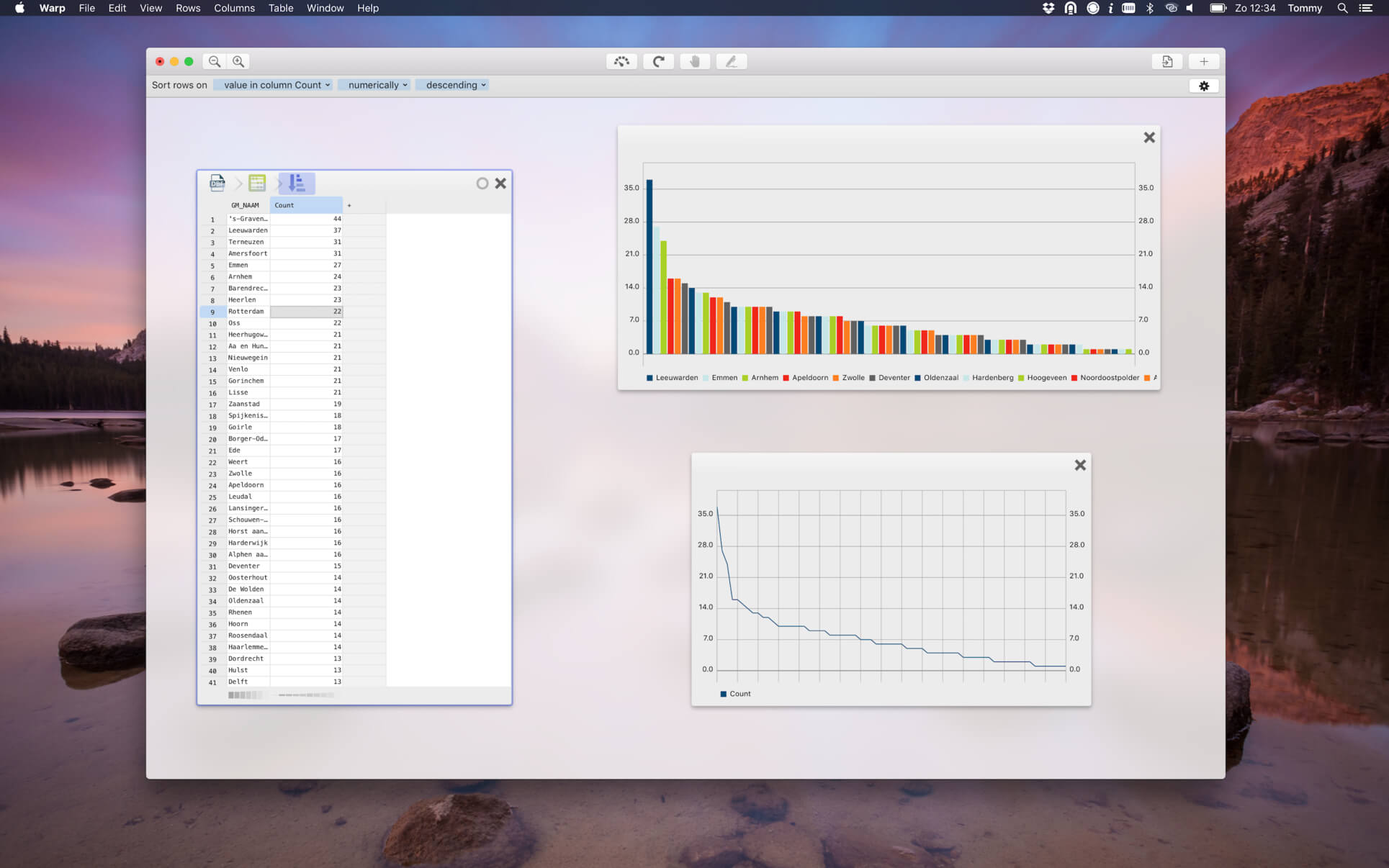
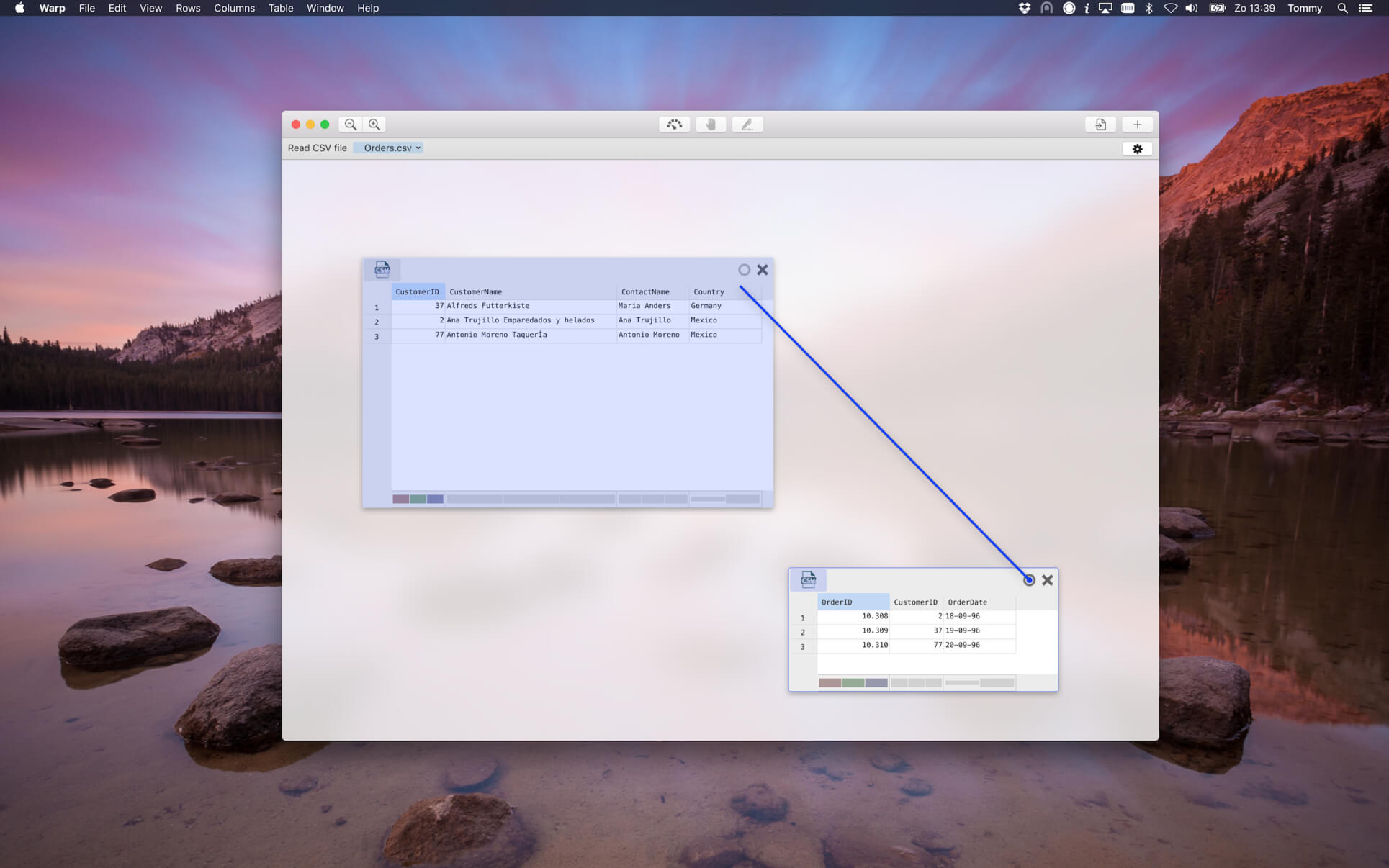
- Title: Warp 4.2
- Developer: Pixelspark
- Compatibility: macOS 10.11 or later
- Language: English
- Includes: K'ed by HCiSO
- Size: 12.59 MB
- View in Mac App Store
Users of Guests are not allowed to comment this publication.